Microservices are a type of software architecture where large applications are made up of small, self-contained units working together through APIs that are not dependent on a specific language. Each service has a limited scope, concentrates on a particular task and is highly independent. This setup allows IT managers and developers to build systems in a modular way. In his book, "Building Microservices," Sam Newman said microservices are small, focused components built to do a single thing very well.
Martin Fowler's "Microservices - a Definition of This New Architectural Term" is one of the seminal publications on microservices. He describes some of the key characteristics of microservices as:
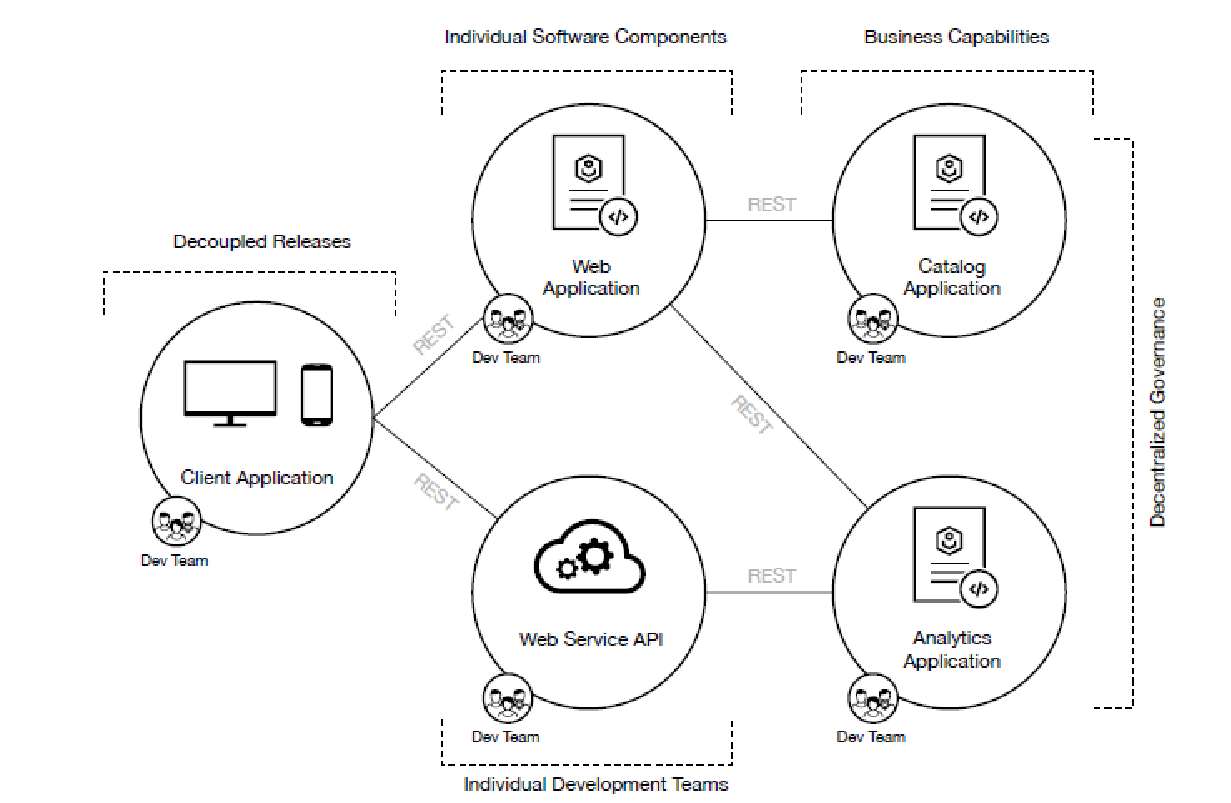
Componentization: Microservices are independent units that are easily replaced or upgraded. The units use services to communicate with things like remote procedure or web service requests.
Business capabilities: Legacy application development often splits teams into areas like the "server-side team" and the "database team." Microservices development is built around business capability, with responsibility for a complete stack of functions such as UX and project management.
Products rather than projects: Instead of focusing on a software project that is delivered following completion, microservices treat applications as products of which they take ownership. They establish an ongoing dialogue with a goal of continually matching the app to the business function.
Dumb pipes, smart endpoints: Microservice applications contain their own logic. Resources that are often used are cached easily.
Decentralized governance: Tools are built and shared to handle similar problems on other teams.
History of microservices
The phrase "Micro-Web-Services" was first used at a cloud computing conference by Dr. Peter Rodgers in 2005, while the term "microservices" debuted at a conference of software architects in the spring of 2011. More recently, they have gained popularity because they can handle many of the changes in modern computing, such as:
- Mobile devices
- Web apps
- Containerization of operating systems
- Cheap RAM
- Server utilization
- Multi-core servers
- 10 Gigabit Ethernet
The concept of microservices is not new. Google, Facebook, and Amazon have employed this approach at some level for more than ten years. A simple Google search, for example, calls on more than 70 microservices before you get the results page. Also, other architectures have been developed that address some of the same issues microservices handle. One is called Service Oriented Architecture (SOA), which provides services to components over a network, with every service able to exchange data with any other service in the system. One of its drawbacks is the inability to handle asynchronous communication.
How microservices differ from service-oriented architecture
Service-oriented architecture (SOA) is a software design where components deliver services through a network protocol. This approach gained steam between 2005 and 2007 but has since
lost momentum to microservices. As microservices began to move to the forefront a few years ago, a few engineers called it "fine-grained SOA." Still others said microservices do what SOA should have done in the first place.
SOA is a different way of thinking than microservices. SOA supports Web Services Definition Language (WSDL), which defines service end points rigidly and is strongly typed while microservices have dumb connections and smart end points. SOA is stateless; microservices are stateful and use object-oriented programming (OOP) structures that keep data and logic together.
Some of the difficulties with SOA include:
SOA is heavyweight, complex and has multiple processes that can reduce speed.
While SOA initially helped prevent vendor lock-in, it eventually wasn't able to move with the trend toward democratization of IT.
Just as CORBA fell out of favor when early Internet innovations provided a better option to implement applications for the Web, SOA lost popularity when microservices offered a better way to incorporate web services.
Problems microservices solve
Larger organizations run into problems when monolithic architectures cannot be scaled, upgraded or maintained easily as they grow over time. Microservices architecture is an answer to that problem. It is a software architecture where complex tasks are broken down into small processes that operate independently and communicate through language-agnostic APIs.
Monolithic applications are made up of a user interface on the client, an application on the server, and a database. The application processes HTTP requests, gets information from the database, and sends it to the browser. Microservices handle HTTP request response with APIs and messaging. They respond with JSON/XML or HTML sent to the presentation components. Microservices proponents rebel against enforced standards of architecture groups in large organizations but enthusiastically engage with open formats like HTTP, ATOM and others.
As applications get bigger, intricate dependencies and connections grow. Whether you
are talking about monolithic architecture or smaller units, microservices let you split
things up into components. This allows horizontal scaling, which makes it much easier to
manage and maintain separate components.
The relationship of microservices to DevOps
Incorporating new technology is just part of the challenge. Perhaps a greater obstacle is developing a new culture that encourages risk-taking and taking responsibility for an entire project "from cradle to crypt." Developers used to legacy systems may experience culture shock when they are given more autonomy than ever before. Communicating clear expectations for accountability and performance of each team member is vital. DevOps is critical in determining where and when microservices should be utilized. It is an important decision because trying to combine microservices with bloated, monolithic legacy systems may not always work. Changes cannot be made fast enough. With microservices, services are continually being developed and refined on-the-fly. DevOps must ensure updated components are put into production, working closely with internal stakeholders and suppliers to incorporate updates.
The move toward simpler applications.
As DreamWorks'
Doug Sherman said on a panel at the Appsphere 15 Conference, the film-production company tried an SOA approach several years ago but ultimately found it counterproductive. Sherman's view is that IT is moving toward simpler applications. At times, SOA seemed more complicated than it should be.
Microservices were seen as an easier solution than SOA, much like JSON was considered to be simpler than XML and people viewed REST as simpler than SOAP. We are moving toward systems that are easier to build, deploy and understand. While SOA was initially designed with that in mind, it ended up being more complex than needed.
SOA is geared for enterprise systems because you need a service registry, a service repository and other components that are expensive to purchase and maintain. They are also closed off from each other.
Microservices handle problems that SOA attempted to solve more than a decade ago, yet they are much more open.
How microservices differ among different platforms
Microservices is a conceptual approach, and as such it is handled differently in each language. This is a strength of the architecture because developers can use the language they are most familiar with. Older languages can use microservices by using a structure unique to that platform. Here are some of the characteristics of microservices on different platforms:
Java
Avoids using Web Archive or Enterprise Archive files
Components are not auto-deployed. Instead, Docker containers or Amazon Machine Images are auto-deployed.
Uses fat jars that can be run as a process
PHP
REST-style PHP microservices have been deployed for several years now because they
are:
- Highly scalable at enterprise level
- Easy to test rapidly
Python
- Easy to create a Python service that acts as a front-end web service for microservices in other languages such as ASP or PHP
- Lots of good frameworks to choose from, including Flask and Django
- Important to get the API right for fast prototyping
- Can use Pypy, Cython, C++ or Golang if more speed or efficiency is required.
Node.js
Node.js is a natural for microservices because it was made for modern web applications.
Its benefits include:
- Takes advantage of JavaScript and Google's high-performance, open-source V8 engine
- Machine code is optimized dynamically during runtime
- HTTP server processes are lightweight
- Nonblocking, event-driven I/O
- High-quality package management
- Easy for developers to create packages
- Highly scalable with asynchronous I/O end-to-end
.NET
In the early 2000s, .NET was one of the first platforms to create applications as services
using Simple Object Access Protocol (SOAP), a similar goal of modern microservices.
Today, one of the strengths of .NET is a heavy presence in enterprise installations. Here
are two examples of using .NET microservices:
Responding to a changing market
The shift to microservices is clear. The confluence of mobile computing, inexpensive hardware, cloud computing and low-cost storage is driving the rush to this exciting new approach. In fact, organizations do not have any choice. Matt Miller's article in The Wall Street Journal sounded the alarm; "I
nnovate or Die: The Rise of Microservices" explains that software has become the major differentiator among businesses in every industry across the board. The monolithic programs common to many companies cannot change fast enough to adapt to the new realities and demands of a competitive marketplace.
Service-oriented architecture attempted to address some of these challenges but eventually failed to achieve liftoff. Microservices arrived on the scene just as these influences were coming to a head; they are agile, resilient and efficient, qualities many legacy systems lack. Companies like Netflix, Paypal, Airbnb and Goldman Sachs have heeded the alarm and are moving forward with microservices at a rapid pace.